Building a Single Customer View Across CRM, Marketing and Analytics


By Steven Renwick, CEO & co-founder, Tilores.
TL;DR: Build a single customer view by ingesting records from CRM, marketing, analytics and warehouse systems, resolving identity at ingestion, storing one profile with lineage, and letting each downstream system query the current resolved context instead of matching customers separately.
Build it on your data: book a demo to see identity resolution across CRM, marketing and analytics, or get the evaluation build to test it locally — then explore the Tilores entity resolution software and its real-time GraphQL API reference.
How do you build a single customer view, step by step?
The build sequence is straightforward, but the boundary matters. The identity layer should resolve and update profiles when records arrive. CRM, marketing and analytics should then query the current profile, not each run its own merge logic.
- Inventory the source records. List every system that creates or changes customer data: CRM contacts and leads, marketing automation contacts, product analytics user IDs, support records, billing records and warehouse tables.
- Define the profile contract. Decide which fields belong in the resolved profile, which fields remain source-specific, which identifiers are trusted, and which systems are allowed to read or write each value.
- Resolve identity at ingestion. Submit each new or changed source record into the identity-resolution layer and use deterministic rules, probabilistic matching and fuzzy matching to connect records that represent the same person or account.
- Persist one resolved profile with lineage. Store the resolved customer profile as one entity made from many records, while keeping the source record IDs, match evidence, merge history and deletion path intact.
- Retrieve the current context at query time. When CRM, marketing or analytics needs customer context, query the resolved profile instead of rebuilding the entity from raw records in the consuming application.
- Push identifiers back carefully. Sync stable profile IDs or selected attributes back to source systems only where they improve workflow, attribution or activation without turning every system into another master.
- Operate consent, access and deletion as first-class flows. Treat access requests, erasure, consent changes and audit questions as product requirements, not as cleanup work after the identity layer is live.
What is a single customer view?
A single customer view is one resolved profile for a customer or account, built from the records that describe them across systems. In data-management terms, this is identity resolution, entity resolution or record linkage applied to customer context. It is not just a dashboard. It is the identity-aware context that CRM, marketing, analytics and customer-facing applications can use consistently.
In practice, the profile has two parts. The first is the current view: names, emails, addresses, account links, lifecycle status, consent fields, product usage and other attributes that consumers need. The second is the lineage: which source records contributed, which rules or fuzzy matches connected them, and how a record can be corrected, split or deleted later.
That lineage is why identity resolution matters. If two HubSpot contacts, a Salesforce lead, a product analytics user ID and a warehouse row refer to the same person, the answer should not depend on which system you query first. The resolved profile should make that connection explicit.
Why do CRM, marketing and analytics drift out of sync?
They drift because each system optimises for its own job. Salesforce REST object documentation describes objects and records addressed through sObject APIs. HubSpot CRM Contacts API documentation describes contact records for individuals and syncing contact data with other systems. GA4 User-ID documentation describes user IDs for connecting signed-in activity across sessions, devices and platforms.
Those are all useful local models. They are not the same identity model. CRM may treat a lead and contact as separate records. Marketing automation may hold an old email address. Product analytics may see an anonymous user before login and a known user afterwards. The warehouse may carry historical snapshots that are correct for analysis but stale for a live workflow.
Most teams first try to repair this with exports, sync jobs and manual merge rules. That can work for a small number of clean records. It breaks down when identifiers are missing, emails change, names are misspelled, B2B accounts have subsidiaries, or records arrive continuously from multiple sources.
The more durable answer is to treat identity as a layer. Source systems keep doing what they do well. The identity layer accepts their records, resolves them into entities, and gives every consuming workflow the same current customer context.
Where should the single customer view sit in the architecture?
The architecture should fan in, then fan out. CRM, marketing automation, product analytics and warehouse tables send source records into the identity-resolution layer. Resolution happens during ingestion: the layer normalises fields, applies exact rules where they are safe, uses probabilistic and fuzzy matching for messy data, and updates the resolved entity.
The consuming systems should not assemble the entity again. At query time, they retrieve the current resolved context: the entity ID, source records, selected profile fields, match evidence, duplicates, and any fields exposed through the query model. This keeps CRM, marketing and analytics aligned because they all start from the same resolved entity.
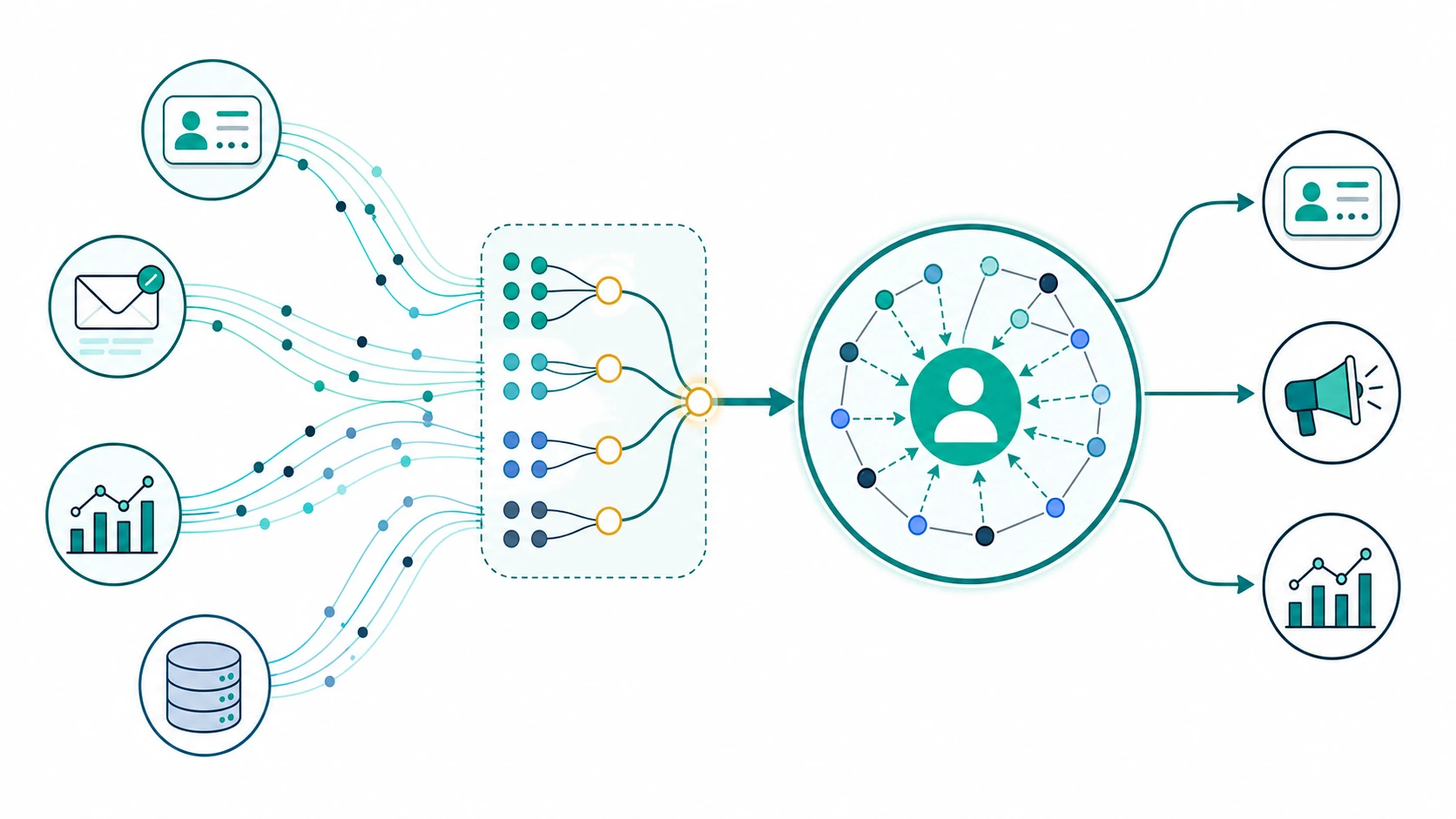
This boundary also keeps operations clean. If a source record changes, you process that change once. If two records should split, the identity layer holds the split logic and connection history. If an access request arrives under GDPR Article 15, the team can trace which records belong to the person and which systems contributed them.
Where does a single customer view sit next to your CDP, MDM and warehouse?
A resolved-identity layer sits next to CDP, MDM, data governance and warehouse systems. It is not a substitute for them. A CDP may still manage audiences, journeys and activation. MDM may still define the broader master-data operating model. The warehouse remains the right place for analytics, modelling and historical queries.
The identity layer has a narrower job: decide which records represent the same customer or account, keep that decision current, and expose the resolved context to other systems. That narrowness is useful. It lets a marketing journey, sales workflow, analytics report and support assistant start from the same identity decision without forcing every system to become the master.
This is especially important when data is messy. Deterministic rules are valuable when exact identifiers are reliable. Probabilistic and fuzzy matching are necessary when names, addresses, phone numbers and account details vary. Tilores’ fuzzy matching algorithms page explains why flexible matching is needed for real customer data, and the identity resolution glossary gives the core vocabulary.
How does Tilores support this pattern?
Tilores is built as a dedicated identity-resolution and entity-resolution layer for this kind of fan-in architecture. Source records are submitted through the Tilores GraphQL API reference, where the submit mutation adds records and entity queries retrieve resolved entities by entity ID, record ID or search parameters.
The Tilores schema customization docs show how the input and output record model can be adapted to the customer’s data model. That matters for a single customer view because CRM, marketing automation, analytics and warehouse records rarely share one clean schema.
The product boundary is also practical. Tilores can feed a CRM workflow, a marketing activation flow, a warehouse job or an application that needs a current customer view. It sits beside the systems you already use rather than pretending to be all of them. For broader product context, see the Tilores features page and the guide to building an identity resolution system.
What are the common failure modes?
The first failure mode is making the warehouse the only place where identity is resolved. That can be fine for reporting, but operational workflows often need the current profile while the customer is still in the workflow. Batch-only warehouse logic can leave CRM, marketing and product applications acting on stale context.
The second failure mode is pushing merge logic into every consumer. If CRM, marketing and analytics each maintain separate match rules, they will eventually disagree. One workflow may merge two records that another workflow keeps separate. That is how the same person becomes three different customers.
The third failure mode is treating matching as a set of exact rules and nothing more. Exact email matching is useful, but it is not enough for changed domains, alternate names, address variations, shared phones, subsidiaries, or typographical errors. A reliable single customer view needs deterministic, probabilistic and fuzzy matching under one explainable model.
The fourth failure mode is forgetting governance. GDPR Article 4 treats identifiers such as names, identification numbers, location data and online identifiers as part of personal-data context when they relate to an identifiable person. GDPR Article 15 gives the person a right of access. The identity layer therefore needs lineage, access controls and deletion paths from the start.
FAQ
What is the difference between a single customer view and a CDP?
A single customer view is the resolved customer profile your systems can use. A CDP may activate marketing audiences and often includes identity features, but a dedicated identity-resolution layer sits next to the CDP when matching depth, explainability or real-time API access needs to be stronger.
Should a single customer view be built in the warehouse?
The warehouse is useful for analysis and historical modelling, but it is not always the right runtime layer for operational identity. If CRM, marketing or analytics needs the current resolved profile during a live workflow, resolve identities at ingestion and query the current profile through an API.
When should identity resolution happen?
Identity resolution should happen when source data is ingested or changed. Query time should retrieve the current resolved context. If every consuming system runs its own matching during the consuming query, the same person can be matched differently in different workflows.
What systems should consume the resolved profile?
CRM, marketing automation, product analytics, support, risk systems and warehouse jobs can all consume the resolved profile. The important boundary is that they consume the same resolved identity layer instead of each maintaining a separate matching model.
See what resolved entity data does for your business — and your AI.