How to Stop AI Agents Acting on Stale or Fragmented Customer Data


By Steven Renwick, CEO & co-founder, Tilores.
TL;DR: Stop AI agents acting on stale or fragmented customer data by fixing the customer context layer before the model reasons. Detect fragmented records, resolve them at ingestion, retrieve the current resolved customer context at query time, and keep source updates flowing into the resolved record.
Give AI agents current resolved customer context: book a demo to see real-time identity resolution on your data, or get the evaluation build to try it locally — then explore Tilores IdentityRAG for the retrieval pattern behind it.
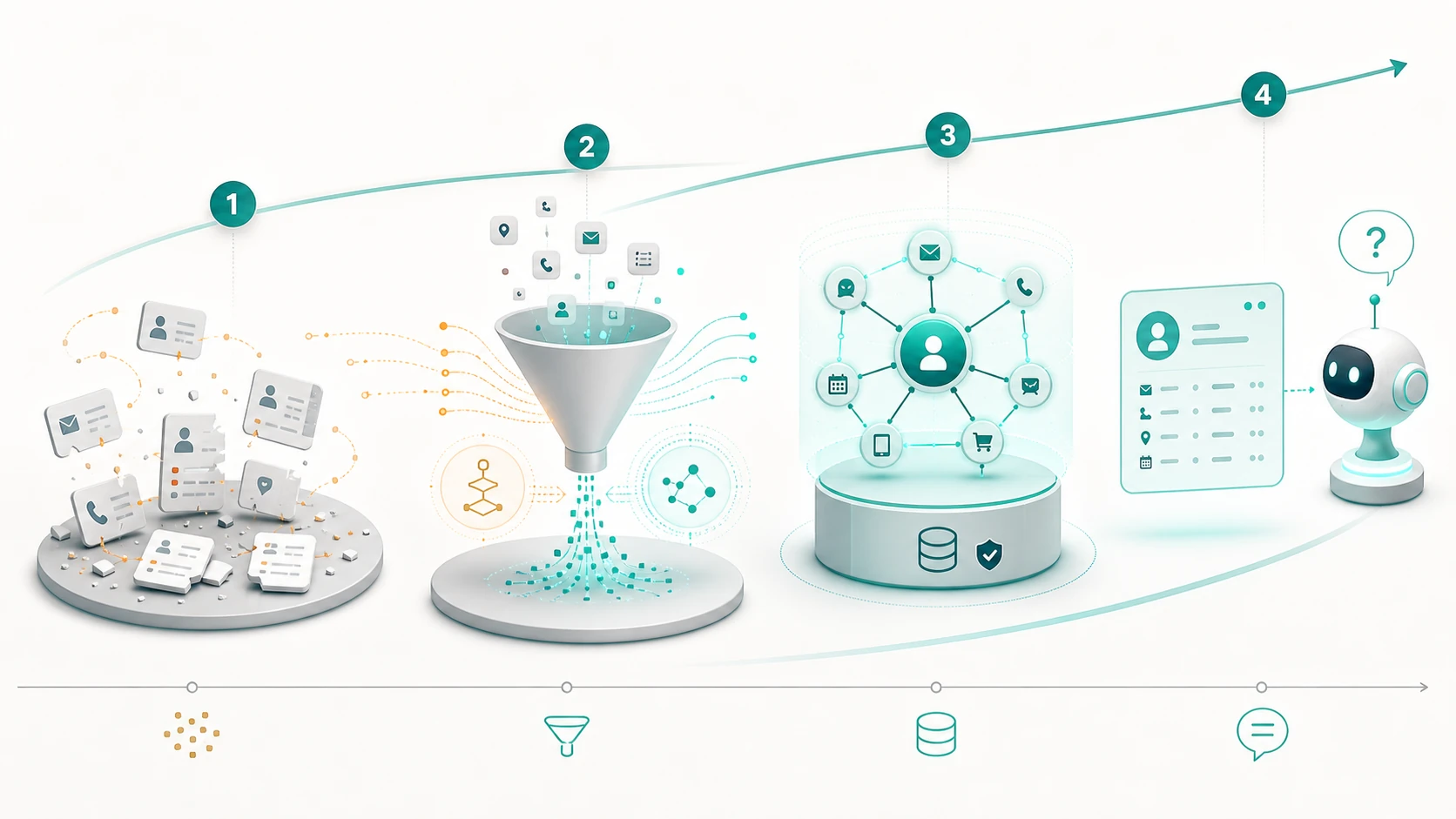
The four-step process
- Detect fragmentation before the agent sees it. Identify duplicate, stale and conflicting customer records across CRM, support, billing, marketing and product systems before they are eligible for retrieval.
- Resolve customer records at ingestion. Submit incoming records to the identity-resolution layer, link them to the right entity using deterministic rules and probabilistic or fuzzy matching, and retain the evidence.
- Retrieve current resolved context at query time. Give the agent a controlled query-time tool that returns the already-resolved customer context, not raw fragments from every source system.
- Keep the resolved context fresh. Re-submit source updates, deletions, splits and corrections so the resolved record changes as the customer state changes.
How do you stop AI agents using stale customer data?
The reliable pattern is to stop treating the language model as the place where customer identity gets repaired. The agent should receive a current, resolved customer context that has already been assembled by the identity layer.
Retrieval-augmented generation, as described by Lewis et al. in the original RAG paper, gives a model external context at generation time. That helps only if the retrieved context is the right context. If retrieval returns five stale or partial customer fragments, the model can still write a confident answer from the wrong facts.
For customer-aware agents, the context layer needs two jobs. First, resolve records before retrieval. Second, retrieve the current resolved context when the agent asks a question. Tilores rules documentation describes the assembly process after records are submitted, while the Tilores API reference shows search and entity queries returning records, edges, duplicates, hits, score and hitScore.
What are the symptoms of stale or fragmented customer data?
You usually see the problem before you can name it:
- The same customer appears as separate records in CRM, billing, support and marketing.
- The agent answers from an old email, old address, closed account or previous plan.
- Two systems disagree about account status, consent, risk state or entitlement.
- Search returns multiple plausible people with the same name or company.
- A support agent has to check another system because the AI answer feels incomplete.
- The agent gives a polished answer but cannot show which source record made the fact current.
These symptoms are not prompt problems. They are data assembly and retrieval problems. A stronger instruction can tell an agent to be careful, but it cannot make stale source data current or merge customer fragments after they have already entered the context window.
Why should fragmentation be detected before an agent retrieves context?
Detection belongs upstream because retrieval is a narrowing step. Once the agent has received the wrong fragments, the model has to infer which ones belong together, which ones are old, and which ones should be ignored. That is a fragile control for customer data.
Start by looking for duplicate identifiers, conflicting timestamps, stale source fields, shared household or company identifiers, and partial records that only become useful when linked to another source. The useful output is not a vague data-quality score. It is a routing decision: resolve automatically, route for review, split a bad merge, or block the agent from acting.
NIST’s AI Risk Management Framework frames valid and reliable AI systems as a core trustworthy-AI characteristic. In customer workflows, reliability depends heavily on whether the model is grounded in current and correctly linked customer facts.
How should records be resolved at ingestion?
Records should be submitted to the identity-resolution layer when they arrive or change. Resolution and assembly happen at ingestion. Query time is for retrieving the already-resolved customer context.
Do not reduce matching to exact keys. Production identity resolution uses deterministic rules where strong identifiers are available, and probabilistic or fuzzy ML matching where real records disagree on names, addresses, emails, phones or devices. Fellegi-Sunter record linkage is the classic reference point for probabilistic linkage; modern systems add workflow controls, graph handling, review paths and operational APIs.
In Tilores, records are connected into entities during assembly after submission. Rules define how records link, and the resulting entity carries records and edges that explain why data belongs together. That evidence matters because an agent workflow needs to know whether it is looking at a clean single customer, a weak match, or a case that requires review.
The important boundary is this: the agent is not assembling the entity during the conversation. The identity layer has already done that work. The agent asks for the resolved context and receives only what the workflow allows it to use.
How should an agent retrieve current resolved context at query time?
Give the agent one controlled customer-context tool. The tool accepts identifiers from the conversation, queries the resolved identity layer, and returns a scoped context object.
A useful context object includes the resolved entity ID, candidate count, allowed customer fields, source-system IDs, match evidence, freshness indicators and an action policy. The model may write the response, but the workflow decides whether the evidence permits answering, asking for another identifier or escalating.
The Tilores API reference shows the difference between entity retrieval and search. Entity queries return the records and edges for a known entity. Search queries can return candidate entities with hits, score and hitScore, where score reflects overall match quality inside the entity and hitScore reflects alignment with the submitted search parameters. Those signals should inform routing. They should not be copied into universal thresholds without calibration on your own data.
For an AI support agent, the retrieved payload should be small. It should not include every CRM note, every ticket and every invoice. It should include the current fields the agent is allowed to use, plus enough provenance for the workflow and a human reviewer to trace the answer later.
How do you keep resolved customer context fresh?
Freshness is not a one-time migration. It is an operating loop.
Every source update that changes the customer state should flow back into the resolution layer: new records, changed emails, closed accounts, deleted records, consent changes, merged accounts, split corrections and reviewed edge decisions. If the source system changes but the resolved context does not, the agent will eventually act on a stale fragment.
That loop needs deletion and correction handling, not only matching. Tilores’ API documentation includes disassembly behavior for removing records or edges and splitting entities when a connecting link is removed. That matters because freshness includes knowing when two records should no longer be treated as one customer.
Keep freshness visible in the tool response. The agent workflow should know which fields came from which source, when the source last changed, and whether the current answer depends on a reviewed or automatically linked edge. A fluent answer should never hide stale evidence.
What should sit next to MDM, CDP, governance, KYC-AML and the warehouse?
The identity-resolution layer should sit alongside those systems, not displace them.
MDM governs master data and stewardship. A CDP activates customer audiences and journeys. Data governance defines policy and access. KYC-AML systems screen and investigate regulated risk. The warehouse supports analytics. Those systems remain valuable, but they are not always the runtime layer an AI agent should call for fresh customer context.
The runtime layer should resolve customer records as they arrive, keep the entity current, and expose query-time retrieval for the application. The Tilores Customer Identity Intelligence page describes the need to unify scattered internal customer data in real time, while the Tilores EntityRAG article explains why customer-specific prompts need entity resolution alongside vector retrieval.
This is the practical division of labor: systems of record keep doing their jobs, and the agent receives a current resolved context from the identity layer when it needs to act.
How should this be tested before an agent is trusted?
Test with the ugly cases, not the clean demo cases.
Use changed emails, shared company domains, family addresses, duplicate billing IDs, migrated CRM contacts, reused phone numbers, transliterated names, stale consent fields and known non-matches. Include over-merge cases where two real people should stay separate and under-link cases where one real customer remains split.
Track false positives and false negatives separately. A false positive can leak or misuse customer data because two people were treated as one. A false negative can make the agent miss history, deny entitlement or create duplicate work. One blended accuracy number hides which risk is getting worse.
Keep the language model out of the final match decision. The Tilores article on LLMs and entity resolution is careful on this point: LLMs can help around extraction or review, but customer identity matching should be repeatable, scored and auditable before the model receives customer context.
FAQ
How do I give AI agents fresh customer context?
Resolve customer records before the agent retrieves them, then expose a narrow tool that returns the current resolved customer context with source IDs, confidence signals and allowed fields. The agent should not search raw CRM, support, billing and marketing fragments directly.
Should customer records be resolved at ingestion or at query time?
Resolve and assemble records at ingestion. Query time is for retrieving the already-resolved, current customer context. If the agent assembles identity during the conversation, stale fragments and ambiguous matches have already entered the prompt.
What is the difference between stale data and fragmented data?
Stale data is old or superseded information, such as a closed account or previous address. Fragmented data is current information split across systems. AI agents often fail when both problems appear together.
Does Tilores take over MDM, a CDP or a warehouse?
No. Tilores should sit alongside MDM, CDP, governance, KYC-AML systems and the warehouse as an identity-resolution and retrieval layer. Those systems still own stewardship, activation, policy, screening or analytics jobs.
Can an LLM fix fragmented customer records by itself?
Not reliably as the production control. An LLM can help extract identifiers or summarize evidence, but matching should be repeatable, scored and auditable outside the model before customer context is retrieved.
See what resolved entity data does for your business — and your AI.