How to Deduplicate Customer Data at Scale (2026)

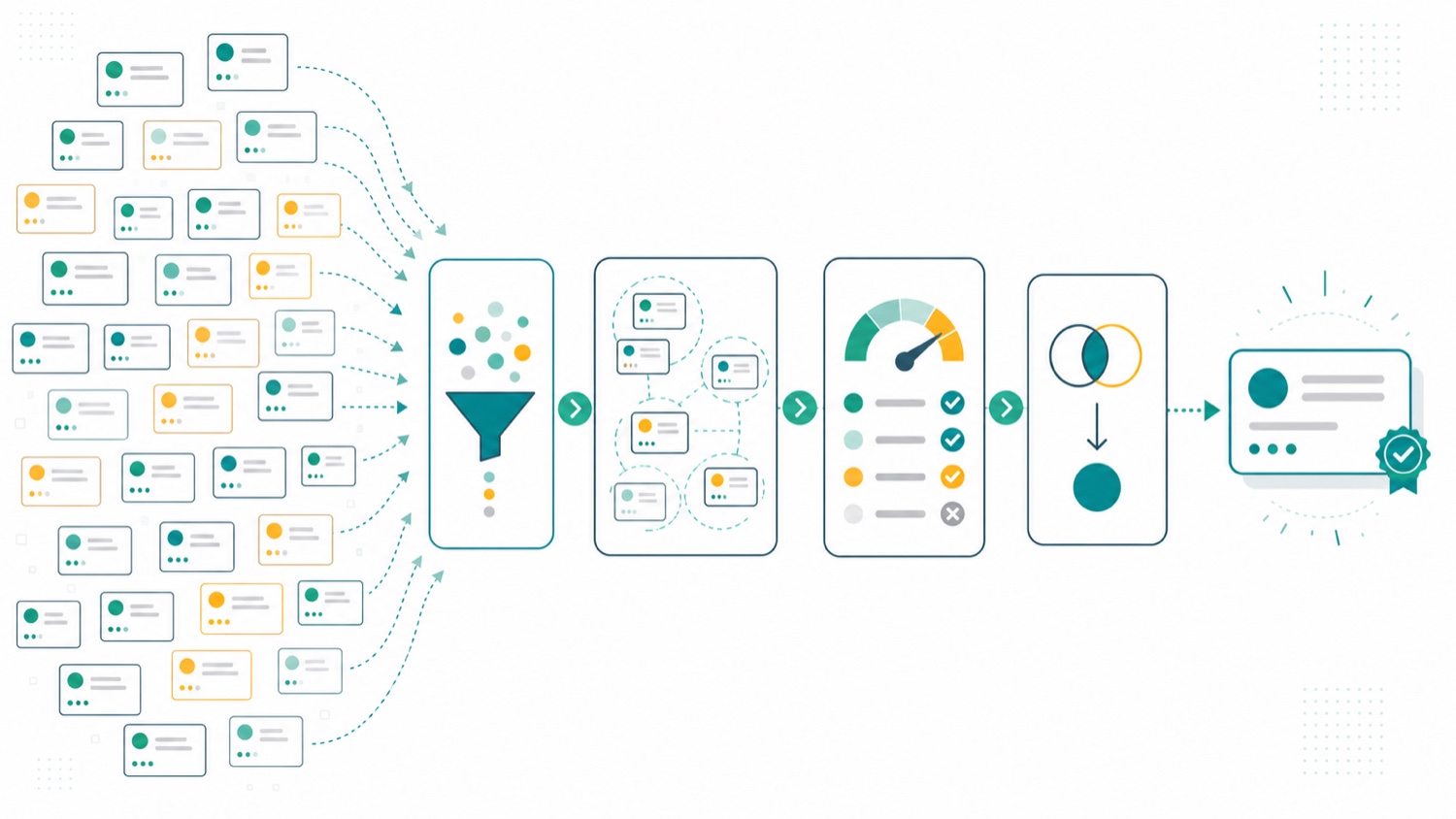
TL;DR: Deduplicate customer data at scale by profiling source systems, normalizing match fields, reducing comparisons with blocking, scoring candidates with deterministic, probabilistic and fuzzy methods, setting confidence thresholds, preserving lineage, and keeping resolved records current through both batch cleanup and real-time ingestion.
Ready to test customer deduplication on real records? Book a demo to see real-time matching on your own data, or get the evaluation build to try it locally, then read the data deduplication software overview and the Tilores GraphQL API reference.
How do you deduplicate customer data at scale?
The build sequence is not just "find duplicate emails and merge." That works only when identifiers are clean and the risk is low. Scaled customer deduplication needs a repeatable process that keeps the match decision, the merge decision and the evidence separate.
- Profile source systems and define the entity scope. Inventory the systems that create customer records, identify the fields that can link records, and decide whether the entity being deduplicated is a person, household, account, company or another customer object.
- Normalize the match fields before scoring. Standardize names, emails, phone numbers, addresses, company names and identifiers before matching so the algorithm compares like with like instead of comparing raw system formatting.
- Generate candidate pairs with blocking. Use blocking keys and search indexes to compare plausible records first, reducing the number of comparisons without throwing away the cases that still need fuzzy or probabilistic matching.
- Score matches with deterministic, probabilistic and fuzzy methods. Combine exact rules for trusted identifiers with probabilistic and fuzzy matching for messy names, addresses, emails, phones and account attributes.
- Set confidence thresholds and review bands. Decide which score ranges are safe to merge automatically, which should be rejected, and which require human review or workflow-specific handling.
- Merge or link records with survivorship and lineage. Keep the winning values, source record IDs, match evidence, edge history and split path so a duplicate can be explained, corrected or reversed later.
- Operate batch backfills and real-time updates together. Use batch jobs for historical cleanup and continuous ingestion for live customer workflows, then measure false positives, false negatives, precision, recall and review volume.
What source data should be profiled before matching?
Start with the systems that create or mutate customer identity: CRM, support, billing, product analytics, marketing automation, KYC, fraud, warehouse tables and imported partner data. Each system has its own idea of a customer. The deduplication layer has to make those ideas comparable.
Local duplicate tools are useful signals, but they are not the whole architecture. HubSpot's duplicate-record guidance, for example, is about finding likely duplicates inside HubSpot records. Google Analytics User-ID documentation shows a different identity model: connecting signed-in activity across sessions, devices and platforms. Both are valid local views. Neither is a universal customer identity layer on its own.
Profile the fields that can help or hurt matching: email, phone, address, name, company, tax ID, account number, device ID, CRM ID, source timestamp and consent state. Then mark which fields are stable, which are noisy, which are sensitive, and which systems can update them.
This is where the entity scope matters. Deduplicating people is not the same as deduplicating companies. Household, account and legal-entity deduplication each need different identifiers and different review rules.
How do blocking and candidate generation keep deduplication scalable?
Naive pairwise comparison does not scale. If every record can be compared with every other record, the comparison count grows very quickly. Blocking keeps the workload practical by first grouping records that share a plausible signal, such as a normalized email domain, postcode, phone prefix, account number or phonetic name key.
The Office for National Statistics describes data linkage as linking or matching datasets, and its standard tools for data linkage focus on automating early linkage stages and quality evaluation. That is the right mental model for customer deduplication too: the first job is to make the candidate set small enough to score well.
Blocking is not a single rule. A good system uses several passes. One pass may catch exact email matches. Another may catch phone and postcode. Another may search for similar company names. A final pass may handle records with missing or changed identifiers. The goal is high recall in candidate generation, then disciplined precision at the merge decision.
How should match scores and thresholds be set?
Scoring should combine exact evidence and messy evidence. Exact evidence includes stable identifiers that are trusted for a particular workflow. Messy evidence includes name variants, address changes, typos, transliteration, shared phone numbers, company suffixes and partial records.
Record linkage literature has long treated matching as a probability problem when a unique shared identifier is missing. The NCBI record-linkage overview describes linkage work where records are matched across files, and probabilistic methods are used when exact identifiers are not enough. In customer data, that usually means deterministic rules for the safest identifiers, plus fuzzy and probabilistic scoring for everything customers and systems make messy.
Do not turn a score into a universal truth. A high score in a marketing dedupe job may not be safe enough for credit, fraud or KYC. A low score may still be useful as a review candidate if the customer journey is high value. The threshold should be calibrated against labeled examples and the cost of each mistake.
The ONS Census 2021 linkage methods are a useful public example of this separation: probabilistic scores above a threshold could be accepted automatically when supported by deterministic matching, while other cases went to clerical resolution. The principle applies well to enterprise customer data: automate the obvious, reject the unsafe, and route the middle for review.
How should merges, survivorship and lineage work?
Deduplication has two different decisions. The first is whether two records belong to the same entity. The second is what to do with the values after the records are linked. Keep those decisions separate.
Survivorship decides which value wins when records disagree. The freshest phone number may win in support. A verified legal name may win in KYC. A billing address may be more reliable than a form-fill address. The right rule depends on purpose, source reliability and data sensitivity.
Lineage is not optional. Store source record IDs, source systems, match evidence, confidence scores, manual review decisions, merge history and split paths. The ICO accuracy guidance connects directly to this operational need: personal data should be accurate and kept up to date where necessary. The right to rectification guidance reinforces the practical requirement to correct inaccurate or incomplete personal data.
That is why I prefer linking records into an explainable entity graph rather than deleting history too early. You can present one clean customer view while retaining the evidence needed to explain why the profile exists and how to undo it when the data says the merge was wrong.
When should deduplication be batch, real time or both?
Batch deduplication is right for historical cleanup, migration, warehouse reconciliation and large backfills. It gives teams time to profile data, review samples, tune thresholds and compare before and after results. Most serious programmes start with a batch pass because the past has already created the mess.
Real-time deduplication is right when the customer workflow is live. A sign-up, support conversation, fraud check, KYC review, credit decision, personalization event or AI-agent retrieval step should not wait for tomorrow's cleanup job if the decision depends on current customer identity.
The pattern is both. Use batch to establish the initial resolved graph. Then send new or changed records into the identity-resolution layer as they arrive. At query time, CRM, support, marketing, risk systems and AI tools retrieve the current resolved context instead of rebuilding identity inside each consuming system.
The ICO data minimisation guidance is also relevant here. A query should return the context needed for the workflow, not every attribute the company has ever collected. Deduplication should make customer context more controlled, not more sprawling.
How does Tilores support at-scale customer deduplication?
Tilores is a dedicated identity-resolution and entity-resolution layer for customer data. It sits next to CRM, CDP, MDM, governance, warehouse and operational systems. Those systems keep their jobs. Tilores handles the matching layer and exposes the current resolved customer context through an API.
The Tilores entity resolution software page describes the product boundary: real-time identity resolution for customer records that need fuzzy matching and explainable linking. The fuzzy matching algorithms page explains why flexible matching matters when real records disagree on names, addresses and identifiers. The identity resolution glossary gives the working definitions for blocking, confidence score, data matching, deduplication and related terms.
In implementation terms, the Tilores API reference documents the submit mutation for adding records, plus entity and search queries for retrieving resolved entities. The schema customization docs show how the input and output record model can be adapted to the customer's data model. The entity documentation explains the entity as the resolved object that contains connected records and relationship evidence.
For data teams, the important detail is the boundary: resolution and assembly happen as records are ingested or changed. Query time is for retrieving the current resolved context. That keeps the deduplication decision consistent across live systems.
How should dedup quality be measured in 2026?
Measure false positives and false negatives separately. A false positive is an over-merge: two different customers were treated as one. A false negative is an under-link: the same customer stayed split. They have different business risks, so one blended accuracy number is not enough.
Track precision, recall, review volume, reversal rate, age of unresolved duplicates, source-system disagreement, and time from source change to resolved-context availability. Add workflow-specific measures for the systems that consume the resolved identity: support misroutes, duplicate outreach, KYC review loops, fraud false alarms, marketing suppression errors and AI tool escalation rates.
Use a golden set, but keep refreshing it. Customer data changes. Names change, companies merge, emails move, addresses are reused, and source systems add fields. A static test set quickly becomes an archive of last year's errors.
The useful final test is operational: can a system explain why two records matched, show which source supplied each surviving value, split a bad merge, and retrieve the current customer context through the same interface every consuming workflow uses? If it cannot, the deduplication programme is not finished.
FAQ
What is the best way to deduplicate customer data at scale?
The best pattern is to profile the source systems, normalize the fields, generate candidates with blocking, score records with deterministic, probabilistic and fuzzy matching, set thresholds, preserve lineage, and keep the resolved entity updated as records change.
Should customer deduplication run in batch or real time?
Use batch for historical cleanup, backfills and analytical reconciliation. Use real-time ingestion when CRM, support, fraud, KYC, marketing or AI workflows need the current resolved customer context while the workflow is still happening.
Is exact matching enough for duplicate customer records?
No. Exact matching is useful for trusted identifiers, but customer records often contain changed emails, abbreviations, typos, shared addresses, missing phones and company-name variants. At scale, exact rules need probabilistic and fuzzy matching around them.
How should duplicate records be merged safely?
Merge only when the confidence and business risk justify it. Keep source record IDs, match evidence, selected survivorship rules, reviewed edges and a split path so the organisation can explain, correct or reverse a merge later.
Where does Tilores fit in a deduplication architecture?
Tilores sits as a dedicated identity-resolution and entity-resolution API next to CRM, CDP, MDM, governance, warehouse and operational systems. It resolves records at ingestion and lets applications query the current resolved customer context.
See what resolved entity data does for your business — and your AI.