A brief introduction to data deduplication

TL;DR
- Customer-record deduplication starts with exact duplicates, but cross-system data usually needs a second layer for non-identical duplicates such as changed emails, spelling variants, partial addresses, and differently formatted names.
- At scale, companies should resolve and assemble records at ingestion, preserve source references, and make the current resolved customer context available to downstream queries instead of forcing every team to rebuild matching logic.
- Deduplication is most useful when it improves decisions, not only storage: marketing, support, analytics, compliance, and fraud teams all benefit when duplicate records collapse into a traceable entity view.
Table of Contents
- Decision guide
- Duplicate data is harmful
- What is data deduplication?
- Deduplication in action
- Why is deduplication needed?
- Short answer
- Why exact duplicates are only the first deduplication problem
- Where entity resolution fits in a deduplication workflow
- Why lineage matters when duplicate records are reduced
- How to validate customer deduplication before production
- Frequently Asked Questions
Decision guide
| Duplicate pattern | Recommended approach | Watch-outs |
|---|---|---|
| Exact duplicate records in one system | Use deterministic rules, exact keys, and field-level comparisons to identify records that are clearly identical. | Exact matching is useful but limited. It can miss records where the same customer appears with small spelling, formatting, or identifier changes. |
| Non-identical duplicates across CRM, support, marketing, or warehouse data | Use entity resolution to link records that describe the same real customer even when fields differ. | Keep match evidence and source references so teams can review why records were grouped and correct mistakes. |
| High-volume incoming customer records | Resolve and assemble records at ingestion so new data updates the entity view before downstream tools depend on it. | Validate ingestion throughput, exception handling, and match thresholds on real data before production use. |
| Analytics, marketing, service, or fraud teams need one customer view | Expose a stable entity identifier or resolved context so each team does not create a separate deduplication process. | Avoid hiding the source records. A useful customer view should remain traceable to the systems that supplied the data. |
| Storage reduction is the main goal | Use deduplication to reduce redundant copies, then decide whether customer identity also needs a resolved business view. | Storage savings alone do not solve customer confusion if duplicate records still appear separately in operational workflows. |
Duplicate data is virtually impossible to prevent, and its impact can be a serious drain on organizational resources. Any seasoned data professional will be familiar with the woes of it. In fact, you’re likely to have had the pleasure of dealing with duplicate data before. Whether you have uploaded data to a system yourself through a data import process or have mistakenly created a duplicate entry manually, it’s something easily done.
What’s even more irritating, because of how ubiquitous duplicate data is, it’s pretty much guaranteed to occasionally bypass your data validation when it gets into your system, no matter how good your processes and checks are. And while duplicated data may sound relatively nefarious (save for how annoying it is, at least), it’s a challenge that many businesses ignore to their peril.
Duplicate data is harmful
Once duplicate data enters your ecosystem, it can lead to all sorts of problems and headaches. Losses in productivity, wasted marketing budgets, disjointed customer service, and additional storage costs are just a few of them, and they lead to an estimated annual loss of more than $6 billion to businesses in the United States alone.
If you are working with a lot of data then, it is crucial for you and your data teams to understand the methods of reducing instances of duplicated data for your application to be a success. This is where data deduplication comes in.
What is data deduplication?
In simple terms, data deduplication, or ‘Dedup’ for short, is a process that eliminates excessive copies and other redundant data within a dataset. Deduplication works by deleting this data, leaving a single copy that is stored. Any duplicate or redundant data that is purged is replaced with a reference that points to the stored chunk, thus significantly reducing storage capacity requirements.
Data deduplication can be run as an inline process that operates in real-time as data is being ported into a system. It can also be run as a background process to catch and remove duplicates after data has been written to disk.
Deduplication in action
An identical duplicate is straightforward — if two records have the exact same values for all their fields, then it ticks the box. For non-identical duplicates, the situation is somewhat more complex.
Let’s look at an example.

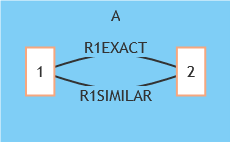
Above we have two simple data records for a person, Jim John Smith. Although all the values that are used for matching are the same, the difference between someData means that this is not an identical duplicate. Visualizing this, it could look something like this:
You may be thinking, “meh, that’s fine”, but this is what four of these records look like:
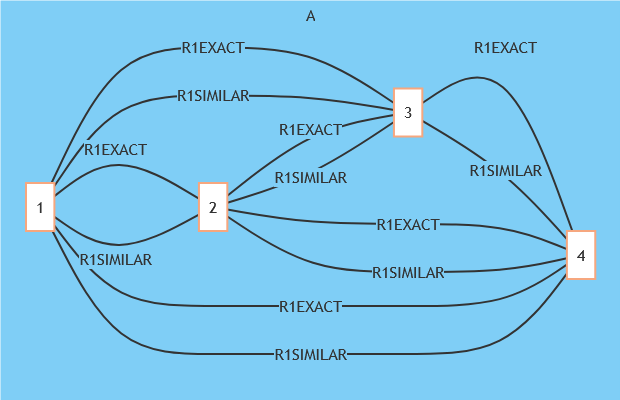
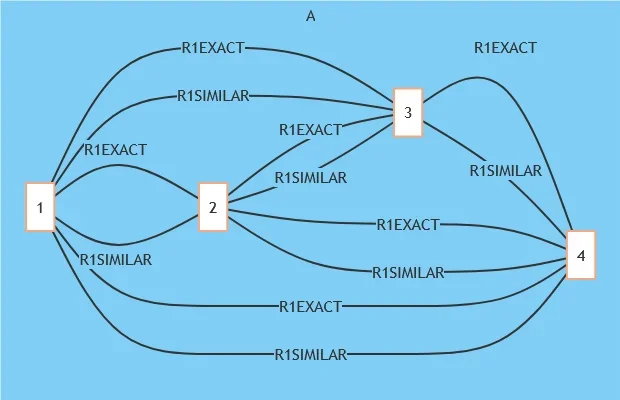
Now multiply this by 40, 400, or even 4,000. But it’s not visualization that’s the biggest problem, it’s the number of records that need to be indexed — this can cause bloating and sluggishness over time while simultaneously inflating costs.
Data deduplication steps in to solve this problem. And although it is a common concept, not all deduplication techniques work the same. In TiloRes, deduplication is managed through rules*. These can be defined in several ways, i.e., to distinguish identical and non-identical duplicates and treat them differently when it comes to indexing. In the excerpt below, the rule R1EXACT has been applied to ensure that the non-identical duplicates above are stored more efficiently.
*We recommend learning more about rules in TiloRes so that you can benefit from a more contextual understanding — helpful information can be found in our documentation and in our demo.

Thanks to deduplication, the four records from before are now stored like this:
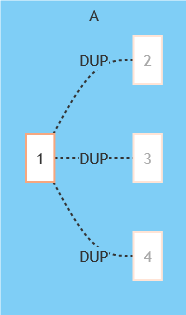
This both saves on storage space and benefits speed because you will only receive a hit on one record when making a search rather than all the records that are available.
Why is deduplication needed?
Although data deduplication is often touted as a way for organizations to reduce their storage costs, there are several other arguably more important reasons why deduplication is needed for all organizations that are tasked with handling large volumes of data.
Deduplication can, for example, enable organizations to quickly back up and store large datasets in the cloud and simultaneously make them available to the C-suite for business insights, or to help them address emerging compliance, regulatory, and data governance challenges. Deduplication can also help to reduce network load, leaving more bandwidth available to dev teams for critical production tasks.
In essence, advanced data deduplication is helping organizations to better manage potentially overwhelming increases in data volume. At the end of the day, this benefits all stakeholders.
If you want to find out more about deduplication, let’s talk!
Short answer
Companies deduplicate customer records across multiple systems by profiling the source data, detecting exact duplicates, resolving non-identical duplicates with matching rules or entity-resolution logic, and storing a stable view that downstream systems can query.
For high-volume customer data, the practical goal is not just to delete extra rows. The goal is to resolve and assemble records as data is ingested, keep lineage back to the original systems, and let query-time workflows retrieve the resolved customer context.
Why exact duplicates are only the first deduplication problem
Exact duplicates are the easiest case because every matching field points to the same record. Customer data becomes harder when two records refer to the same person or company but differ by spelling, address format, email domain, phone number, or source-system convention.
That is why large-scale customer deduplication should not stop at exact matching. It needs a way to resolve non-identical records while keeping enough evidence for review.
Where entity resolution fits in a deduplication workflow
Entity resolution fits after source records arrive and before downstream systems act on them. Records are resolved and assembled at ingestion, then applications, analysts, and AI workflows can retrieve the resolved context at query time.
This placement keeps the source systems intact while giving each downstream workflow a more reliable customer view than raw records alone.
Why lineage matters when duplicate records are reduced
A deduplicated view should not erase where information came from. Customer service, analytics, fraud, and compliance workflows may all need to inspect the source records that contributed to a match.
Preserving lineage also helps teams audit false positives, correct bad merges, and explain why records were treated as one entity.
How to validate customer deduplication before production
Validation should use messy real records rather than only clean samples. Useful tests include nickname variants, changed addresses, duplicate emails, reused phone numbers, partial company names, and similar records that should remain separate.
The evaluation should measure both missed duplicates and incorrect merges, because either failure can damage downstream decisions.
Frequently Asked Questions
- How do companies deduplicate customer records across multiple systems at scale?
- They combine source records, detect exact duplicates, resolve fuzzy or non-identical duplicates, assign a stable entity view or identifier, and preserve lineage back to each source system. At scale, this should happen as records are ingested so query-time workflows can use the current resolved customer context.
- What is data deduplication for customer records?
- Data deduplication is the process of finding and reducing duplicate records so a system does not treat multiple copies as separate customers. For customer data, it often needs to handle both exact duplicates and near-duplicates with different formatting, spellings, or identifiers.
- What is the difference between deduplication and entity resolution?
- Deduplication focuses on removing or reducing duplicate records. Entity resolution goes further by linking records that refer to the same real customer, company, account, or other entity, even when the records are not identical.
- Should customer deduplication run in batch or during ingestion?
- Batch deduplication is useful for historical cleanup, but ingestion-time resolution helps keep the customer view current as new records arrive. Many teams need both: a cleanup pass for existing data and an ingestion path for ongoing updates.
- How can teams avoid bad customer-record merges?
- Teams should test on real data, review edge cases, set conservative thresholds for high-risk workflows, preserve match evidence, and keep a correction path. A deduplication process should reduce duplicates without collapsing distinct customers into one record.
Evaluate Tilores on your own data
Use the next step that matches your evaluation stage.
See what resolved entity data does for your business — and your AI.