What Is Entity Resolution? A Practical Guide for AI, KYC and Customer 360 (2026)

TL;DR: Entity resolution decides which records describe the same real-world person, company or account. It combines deterministic rules, probabilistic matching and fuzzy ML, resolves identity when data is ingested, preserves lineage, and lets KYC, Customer 360 and AI systems retrieve the current resolved context when they need it.
Want to see entity resolution on your own data? Book a demo to watch records resolved in real time, or get the evaluation build to try it locally, then review the Tilores product overview and the GraphQL API reference for how resolved entities are queried in applications.
What is entity resolution?
Entity resolution is the process of deciding which records refer to the same real-world entity. The entity may be a person, company, account, household, device, supplier or legal entity. In customer data, the same idea is often called identity resolution or record linkage.
The job is simple to state and hard to do well: take partial records from different systems, compare their signals, decide which belong together, and keep enough evidence that the decision can be explained or corrected later. The Tilores glossary uses the same vocabulary for entity resolution, identity resolution and record linkage. The broader record-linkage literature also treats entity resolution as a matching problem over imperfect records, which is why deterministic rules alone are rarely enough in real data.
A good entity-resolution layer does not just delete duplicates. It keeps a resolved entity with links back to the source records. That lineage is what lets a team ask why two records were merged, split a bad merge, honor a privacy request, or retrieve the current customer context for an operational workflow.
How is entity resolution different from MDM, IAM, deduplication and Customer 360?
The confusion comes from overlap. Several systems touch identity, but they answer different questions. Entity resolution is the matching and lineage layer. It can feed other systems, but it should not be stretched until it pretends to be all of them.
| Term | The question it answers | How it relates to entity resolution |
|---|---|---|
| Entity resolution | Which records describe the same real-world person, organization, account or other entity? | It is the matching, lineage and resolved-entity layer. It combines exact identifiers, probabilistic evidence and fuzzy matching so downstream systems start from the same identity decision. |
| Deduplication | Which records are duplicates and should be merged, linked or removed? | Deduplication is often one outcome of entity resolution. Entity resolution is wider because it can connect records across many systems and keep source lineage without forcing every source record to disappear. |
| Master data management | What is the operating model for governing master data across the enterprise? | MDM is broader than matching. Entity resolution can sit next to MDM and provide the matching layer behind golden records, survivorship decisions and data stewardship workflows. |
| Identity and access management | Who is allowed to authenticate and access a system? | NIST describes identity, credential and access management as the programs and technologies used to manage identities, credentials and access. Entity resolution links data records about entities. It is not an authorization system. |
| Customer 360 | What should the business know about a customer right now? | Customer 360 is the view. Entity resolution is the identity foundation that decides which records belong in that view. A customer data platform, MDM system, warehouse or application can consume the resolved entity. |
| KYC and AML | Who is the customer, counterparty or beneficial owner, and what related records should be reviewed? | Entity resolution supports KYC and AML by connecting fragmented customer, account and counterparty records. It sits next to screening, case management, policy and human review. |
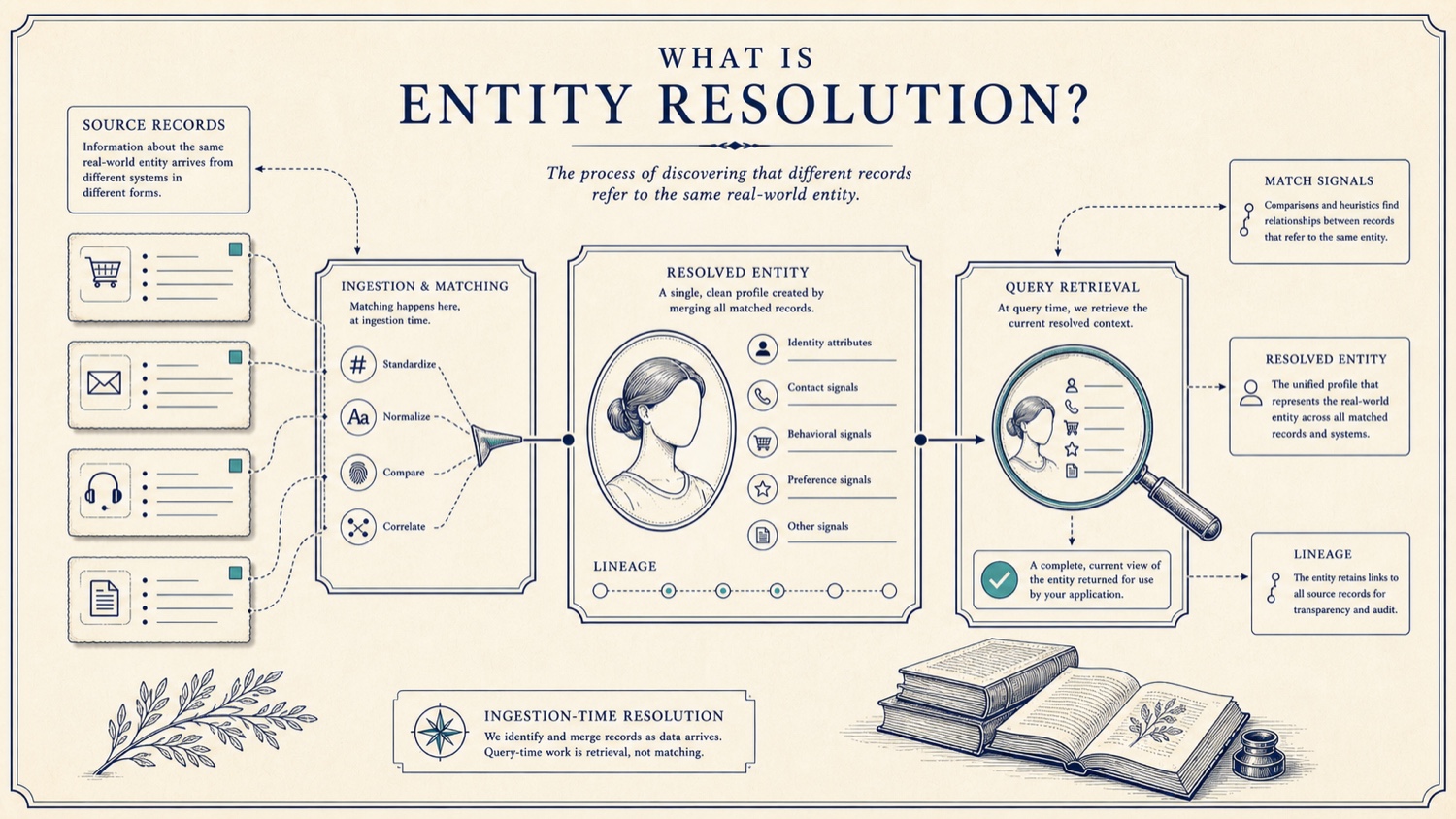
How does entity resolution work in five steps?
The implementation details vary by domain, but the core sequence is consistent. The important boundary is that resolution happens when records arrive or change. Query time should retrieve the current resolved context, not rebuild the entity from raw records again.
- Ingest source records. Bring in customer, account, transaction, support, product, risk or reference records from the systems that create them.
- Standardize and normalize fields. Clean formats where useful, such as casing, whitespace, phone formats, address tokens or schema names, without pretending messy data has become perfect data.
- Compare match signals. Use deterministic rules where identifiers are reliable, such as exact IDs or verified emails, and use probabilistic and fuzzy matching where names, addresses or organization details vary.
- Create or update the resolved entity. Attach records that refer to the same real-world entity, keep the source record links, and update the entity when new evidence arrives.
- Expose the current context. Let applications query the resolved entity, source links, duplicate candidates, match evidence and selected attributes through a stable API.
Tilores follows this pattern through configurable schemas and API access. The Tilores GraphQL API reference covers record submission and entity queries, while the fuzzy matching algorithms guide explains why flexible matching matters when names, addresses and other identifiers are incomplete or inconsistent.
Why does entity resolution matter for KYC and AML?
KYC and AML work depends on knowing which records belong together. A customer may appear under alternate spellings, old addresses, changed emails, subsidiaries, shared phone numbers, multiple accounts or related businesses. If those records stay fragmented, screening and review can miss the connection. If unrelated records are merged too aggressively, the team can create false positives and operational noise.
The regulatory context is not optional. FinCEN's customer due diligence rule addresses identifying and verifying beneficial owners of legal entity customers in covered financial institutions. GDPR Article 4 treats identifiers such as names, identification numbers, location data and online identifiers as part of personal data context, and GDPR Article 15 gives data subjects a right of access.
Entity resolution does not make a compliance decision by itself. It provides the identity substrate that helps compliance systems see the same customer, account, counterparty or beneficial owner consistently. The decisioning, controls, case evidence and audit policy still sit around it.
What does entity resolution give Customer 360 teams?
A Customer 360 view is only as good as the identity decision underneath it. If a CRM contact, billing account, support ticket, product user and marketing profile all describe the same customer, the business needs one current context. If two different people share a name or account domain, the business needs them kept separate.
That is why Customer 360 should not be treated as a dashboard exercise. The dashboard is the last mile. The hard part is the identity layer that keeps records linked, split and updated as data changes. CDPs often include identity features, and MDM programs may govern the master-data operating model, but a dedicated entity-resolution layer is useful when the matching problem is deeper, messier or more operational than the consuming system should own.
For a practical build pattern, the Tilores guide to building a single customer view across CRM, marketing and analytics shows how the resolved profile becomes the common context that other systems read.
Why does entity resolution matter for AI agents?
AI agents and retrieval systems fail quietly when the underlying customer identity is wrong. If the retrieval layer sees five fragments for one customer, the agent may answer from a stale support ticket or miss the latest billing state. If two customers are incorrectly merged, the agent can expose or act on the wrong facts.
The safer pattern is identity before retrieval. Records are resolved at ingestion. The current entity context is retrieved at query time. That gives the agent one stable customer, counterparty or account context to reason over, with source links and lineage still available when a person needs to inspect the result.
Tilores calls this pattern IdentityRAG in its IdentityRAG guide. For implementation work, the LangChain Tilores integration docs and the Tilores LangChain repository show how resolved entity data can be connected to agentic applications without asking the language model to become the matcher.
Where should entity resolution sit in the data stack?
Entity resolution should sit beside the systems that create, govern and consume data. It should not replace the CRM, CDP, warehouse, MDM program, KYC system or data-governance process. Each of those systems still has its own job.
The useful architecture is a shared identity layer. Source systems submit new or changed records. The identity layer resolves them, keeps lineage, and exposes entities through an API. Downstream systems retrieve the current resolved context when they need it.
This is the role Tilores is built for: a dedicated entity-resolution layer that can be embedded next to existing systems rather than forcing the business to rebuild around a new master application. The deeper implementation guide, how to build identity resolution, is a useful next read if you are already designing the ingestion and query boundary.
What should buyers check before choosing entity resolution software?
Start with the shape of the records, not the vendor language. Ask whether the system can handle the identifiers you actually have, not the identifiers you wish you had.
- Matching methods: Does it support deterministic rules, probabilistic evidence and fuzzy matching under one explainable model?
- Lineage: Can every resolved entity show the source records and match evidence behind it?
- Update behavior: What happens when a record changes, a merge is wrong, or a new record arrives?
- API access: Can applications retrieve the current resolved context when a user, analyst or agent needs it?
- Governance fit: Can the layer sit next to MDM, CDP, warehouse, KYC, AML and privacy processes without pretending to replace them?
- Operational review: Can your team inspect, correct and audit matches when the decision matters?
The strongest test is a representative data set. Clean demo records are easy. Real customer, account or counterparty data usually has old addresses, partial names, changed emails, subsidiaries, transliteration issues and missing identifiers. That is where the entity-resolution design proves itself.
FAQ
Is entity resolution the same as deduplication?
No. Deduplication is usually the act of removing or merging duplicate records. Entity resolution is the wider decision layer that finds which records refer to the same person, company or account across systems, keeps lineage, and exposes the resolved entity to other applications.
When should entity resolution happen?
Entity resolution should happen when source data is ingested or changed. At query time, applications and AI agents should retrieve the current resolved context instead of assembling identity from raw records again.
How does entity resolution support KYC and AML?
It helps regulated teams connect customer, account, counterparty and beneficial ownership records that may be fragmented across systems. That supports screening, review and audit, but it sits next to compliance policy, case management and human decisioning.
Does a Customer 360 platform replace entity resolution?
No. Customer 360 is the view or experience the business consumes. Entity resolution is the identity layer that decides which records belong in that view. A CDP, MDM system or warehouse can consume the resolved entity rather than replacing it.
Why does entity resolution matter for AI agents?
AI agents need reliable customer context. If two records for the same customer remain separate, or two different people are wrongly merged, the agent can retrieve the wrong facts. Entity resolution gives retrieval a stable, current entity context.
See what resolved entity data does for your business — and your AI.